“System availability was 99.83% last month! That’s up from 99.75% the previous month!”
Sounds kind of good, no? I mean, that’s a high number, right? Right?
Actually, no. It’s not a very useful number, in and of itself. In fact, I regard the publication of uptime metrics like that as a regrettable symptom of IT focusing on technical aspects, rather than business impacts. Here’s a discussion of why I see it that way, followed by a presentation of an alternative focus providing much more business value.
So, what’s wrong with a time-honored metric like “the system was 99.83% available”?
- The number is deceptive. Few people can mentally translate “99.83% availability” into a more meaningful real number, such as “system was down for 1.3 hours last month.” Even fewer can tell you the real difference between 99.3% uptime (also sounds pretty good, right?) and 99.8% uptime. Both 99.3% and 99.8% look (to the vast majority of business people) at first glance like pretty good numbers for uptime, but the first represents more than three times the number of “down hours” of the second.
- The number is ill-defined. It begs the question of what’s considered down: what if the system is just somewhat degraded in performance? Who decides that it’s down? Who declares that it’s back up? We’ve all seen situations where a technician will insist the system is up, even though no one is able to access it or get sufficient performance to actually use it.
- The number is often not comprehensive in what it includes. Most notably, many shops don’t count scheduled maintenance as downtime when calculating their uptime metric. When you don’t count scheduled maintenance, you’re ignoring potentially many hours of real business impact per month. Scheduled maintenance can’t be a “free pass” for downtime.
- The number doesn’t compare apples to apples. Just tracking total raw downtime considers all outages to be the same, no matter what the time or situation. A ten-minute outage at noon may impact your business much more than an hour-long outage at 3 a.m. An outage that occurs right when you’re running a key campaign to drive people to your site can be especially devastating.
Alternatives
Somewhat better than the “99.83% uptime” style of metric is reporting on the specific number of system DOWN hours or minutes in the period. It’s when the system is down that there’s business impact, so why not use that as your yardstick, instead of the reverse. Some call these “impact hours”, in fact. Stating that the system was unavailable for 20 minutes last week is much clearer (albeit sometimes more distressing!) to most business people, compared to saying it was 99.8% available. Still, though, expressing the figure as down hours doesn’t address the other problems listed above.
The underlying insight here is that raw outage statistics, whether they’re expressed as an uptime percentage or as downtime hours, are nothing but a proxy for business impact. And not a very good one, for the reasons discussed.
Here’s a radical idea: the goal isn’t simply to report and then reduce your downtime per se. Instead, you want to assess, promulgate, and then work down, the total business impact of your outages, and to do that effectively, you need to weight your outages by time of day and traffic. And you need to include every single outage in your assessment of business impact, including maintenance.
What’s the clearest expression of business impact? In a nutshell: DOLLARS. How much did a given outage cost the company, in terms of missed sales and wasted expenses? Yes, there are a lot of factors and assumptions involved in figuring that out, but that’s what models are for. Make some assumptions and build a model that will calculate the specific dollar cost for an outage, based on information about the outage’s duration, site traffic pattern at the time of the outage, etc.
We did exactly this at an internet site where the revenue stream was on the order of a million and a half dollars a week. We incorporated considerations such as the following into our model:
- Upon analysis, we realized that any outage resulted in missed subscriptions, site advertising, and ancillary signups for partner services from which the company derived revenue. We needed the model to incorporate an understanding of the patterns and dollar costs for each of these.
- We also realized that an outage also meant that we’d wasted the money spent on external internet advertising during that outage that was driving people to our site. During an outage, external ads of course kept appearing for our site; people would click on those ads and land on our outage page. Ergo, wasted advertising dollars.
- Outages at different times (hour of day, plus even day of week) were vastly different to our site in terms of business impact and cost. Specific time of the outage needed to be a key part of the calculations of business impact.
- Outage impact also depended on whether it was a high-traffic day or not. A high-traffic day might feature more than ten times the normal volume of traffic and transactions; an outage at that point would therefore arguably cost us ten times as much.
- Not all outages were total: sometimes performance was degraded but access was still possible. We decided to incorporate a “% degradation” parameter in the model for an outage, recognizing that deciding on that percentage would be a judgment call for any outage.
- As noted, most sites don’t count scheduled maintenance in downtime. But that’s still lost revenue. Assessing business impact requires both conservatism and full transparency. We decided to include all outages, scheduled or otherwise, when we published our outage business impact metrics.
Building the model required not just some adept spreadsheet skills, but the up-front accumulation (and regular updating) of various base data to drive the calculations. Specifically, for each hour and day of week, we had to:
- Collect and average our aggregated historical traffic data
- Collect and average aggregated sales revenue numbers
- Determine how to calculate probable advertising revenue
Once built, our model not only let us state our downtime in terms of true business impact (i.e., total dollars for a given period), but it also provided a ready way of analyzing, up front, the specific cost of a planned outage. Using that as a tool, management could much more effectively assess alternatives and opportunity costs when system interventions to address various problems were being considered.
Here’s a snapshot of the model’s inputs (in yellow) and its outputs, slightly altered for presentation:
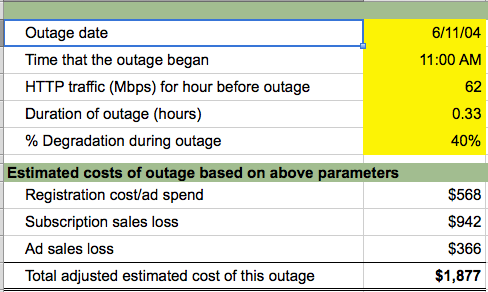
From here, it’s a small step to logging and tracking these total estimated costs across a given time period such as a month. (You should anticipate, by the way, that disclosure of the total dollar cost of outages will tend to invoke far more attention and commentary than the old-style percentage figure ever did! Transparency brings scrutiny. This is a good thing.)
Yes, estimates and aggregations were necessary in coming up with these approximate costs; it’s just a model, after all, with all sorts of incorporated assumptions. And the estimates will never be utterly perfect. But still, they’ll be a far cry better at helping you express the approximate business impact of your downtime than just proudly declaring that the system was “99.83% available” last month.
Lagniappe:
- Publicly visible major SaaS system availability pages:
- Evan L. Marcus, “The myth of the nines”, September 1, 2003
- Continuity Central, “Five Nines: Chasing the Dream?”
- Paul Beckford, “Calculating Server Uptime”, February 13, 2010
- Lenny Rachitsky, “Transparent Uptime” blog
- George Ritchie, Serio Ltd, “Introducing ITIL® Availability Management”

Another side benefit of this lost revenue based model is providing a more realistic context to the irrational business product team and subsequent IT management reaction. Some readers will identify with the product owner that blasts out inflammatory emails demanding that “heads need to roll in IT” for the slightest blip in service. The inflammatory email sends IT management into a “root cause analysis” frenzy followed by irrational costing proposals to avoid future blips in service that will most likely never get implemented. If the outage blip cost $1,877 in lost revenue but the FTE burn to do exhaustive root cause and compose hastily proposed yet impractical solutions costs $10k+ not to mention the negative impact on the parallel in-flight projects, should this overreaction even be warranted?
Agreed, John; but I usually see it go the other way. In other words, when real dollars (rather than an abstract and high-sounding uptime percentage) are attached to outages, people start to PAY ATTENTION. But yes, part of discussing uptime for the CIO is helping to educate his or her peers on the cost of high availability, redundancy, etc. On the positive side, I’ve seen the disclosure of dollar costs of outages help bolster the business case for purchases, repair, maintenance, upgrades: it’s no longer just a “wish list” unattached to real impact. Again, this is a good thing.
Thanks for commenting, as always.
John,
I would be interested in getting your thoughts on systems that don’t have revenue tied to them like email for example. I love your comment Peter on ‘the tech guy thinks the systems are up but the business folks still can’t use the system’. I like the way your break down the communication process for core systems that drag with them some of the obvious core business systems, but what about the email system that is ‘up’ so says the IT tech, but the internet line is down so no external people can access email via Blackberry, OWA, etc. Hi impact situation for sure, but not necesarily a system that drags revenue…. Interested in your thoughts..
Hi Peter, fantastic post as usual. An example of your “work down” advice can be found at BMW. One of their IT metrics is “cars not produced due to IT incidents.” Imagine the governance and process that enables them to make that connection. Amazing!
Steve Romero, IT Governance Evangelist
http://community.ca.com/blogs/theitgovernanceevangelist/
This article and the comments reinforce the longstanding need for a business impact assessment/analysis (BIA) tied to DR/business continuity. As IT organizations move to embrace ITIL and Service Continuity, the interrelationship between availability statistics and costs (hard and soft dollars associated with outages) not only allows for prioritizing service restoration, but links those operational outages and degredations to business metrics.
Many thanks,
Steve Woolley, CBCP, MBCI, PMP
Bill,
I bet the average corporate DR or CP application risk assessment/BIA lists company email as not a mission critical IT service and thus can be restored after other missions critical IT services are restored in the event of a disaster. Yet, if anyone has been in IT at a company when the company email system is down knows that the business community considers email as mission critical as light, heat and power. I recall a past lengthy voice phone outage that didn’t generate near the noise that a brief email outage generated.
Unfortunately, I can’t say I have ever run across anyone with a sure fire way to bring rational reaction to email system outages. I think IT management just needs to accept that certain systems carry a higher up-time requirement based on end user perception rather than the analytical output of a BIA and administer accordingly.
Bill/John,
I completely agree with John that email outages are almost always viewed as critical by the enterprise, even if that’s sometimes disproportionate. My post here pertained largely to revenue-bearing systems, not to internal systems. But that’s not to say that internal systems shouldn’t be heavily prioritized. There are some key differences: email is much more capable than many revenue-bearing systems at supporting a maintenance downtime window, for example, due to its usage pattern and its store-and-forward nature. In general, I wouldn’t recommend trying to come up with a cost model/impact analysis for email, since making assumptions about the business impact of email outages is particularly difficult, case-dependent, and judgment-based. From a policy/practice point of view, it’s not that hard: assume that the bar is 100% availability during business hours (multinational customers will need to architect appropriately), track impact hours of outages (again, not % availability), and as always focus on root cause and process improvement to work those hours down.